
Расшифровка генетического кода — пожалуй, одна из самых замечательных страниц в истории биологии. По-видимому, это первый и чуть ли не единственный пример того, как задача решалась сразу несколькими независимыми группами, работавшими в тесном контакте и постоянно обменивавшимися неопубликованными результатами без проявлений соперничества и попыток опередить коллег за счет сокрытия получаемых данных — своего рода распределенный мозговой штурм. В результате труднейшая проблема была решена за несколько лет.
Началось всё после того, как было установлено, что основным хранилищем и переносчиком генетической информации является длинная линейная молекула ДНК. Встал вопрос о том, как информация, содержащаяся в гене (фрагменте ДНК) в виде последовательности нуклеотидов (элементарных единиц ДНК), переводится в аминокислотную последовательность соответствующего этому гену белка. Пожалуй, первым, кто сформулировал этот вопрос как задачу о кодировании, был физик Георгий Гамов. Вариант кода, предложенный им в статье 1954 г. (1), был наивен с биохимической точки зрения, но сама постановка задачи о поиске соответствия между нуклеотидными и аминокислотными последовательностями была принята сразу, и в первые годы после публикации статьи Гамова было опубликовано еще несколько умозрительных вариантов генетического кода.
Экспериментаторы атаковали проблему кода с двух сторон. На рубеже 50-х и 60-х годов Френсис Крик с коллегами в серии блестящих генетических экспериментов установили, что код непрерывен и троичен (три идущих подряд нуклеотида — кодон — кодируют одну аминокислоту), он не имеет ни перекрываний, ни специальных символов на границах кодонов. Таким образом, считывание кода происходит по тройкам, записанным подряд друг за другом. Крику же принадлежит «центральная догма» — представление о том, что генетическая информация реализуется в два этапа. Сначала ген точно копируется в молекулу так называемой матричной РНК (мРНК), а уже потом происходит трансляция — перевод нуклеотидной последовательности мРНК в белок (рис. 1).
Одновременно несколько групп проводили биохимические эксперименты по синтезу и трансляции искусственных последовательностей нуклеотидов. Для этого использовалась система, включающая все необходимые клеточные компоненты
трансляции. В такую систему добавляли искусственные молекулы РНК, а затем анализировали последовательности полученных белков.
Однако прежде, чем начались эти опыты, встал вопрос о том, сколько, собственно говоря, аминокислот должно соответствовать кодонам в таблице генетического кода.
Дело в том, что химикам известны сотни различных аминокислот; в природных белках их наблюдаются десятки. Было понятно, что не все из них кодируются непосредственно в ДНК, многие должны являться результатом последующих изменений уже синтезированного белка. В замечательной по прозрачности и четкости неопубликованной статье Крика (2), разосланной в виде письма членам основанного Гамовым РНКового клуба — группы ученых, интересовавшихся проблемами генетического кода, был установлен список из 20 аминокислот, непосредственно закодированных в ДНК. Крик отсек аминокислоты, встречающиеся только в отдельных тканях, в коротких пептидах и единичных белках, и не во всех организмах.
Поскольку различных троек кодонов 64 (четыре нуклеотида, три позиции — четыре в кубе), ясно, что генетический код должен быть вырожден: некоторым аминокислотам соответствуютнесколькотро-ек (уже позднее стало ясно, что некоторые из кодонов кодируют не аминокислоту, а «точку» — сигнал конца трансляции данного белка; они называются стоп-кодоны). Немного идеализированный набор экспериментальных данных, доступных к началу 60-х годов, приведен во врезке, и желающие могут испытать себя в деле расшифровки генетического кода.
После того, как в середине 60-х годов расшифровка генетического кода была завершена, какое-то время казалось, что он универсален для всех живых существ. Однако позднее были обнаружены исключения: в кодах некоторых организмов наблюдаются небольшие отличия от универсального.
Эти отличия чрезвычайно интересны, поскольку они позволяют понять, каким образом происходит эволюция генетического кода и, тем
короткое название нуклеотидная последовательность аминокислотная последовательность (при периоде нуклеотидной последовательности 3 -смесь аминокислотных последовательностей)
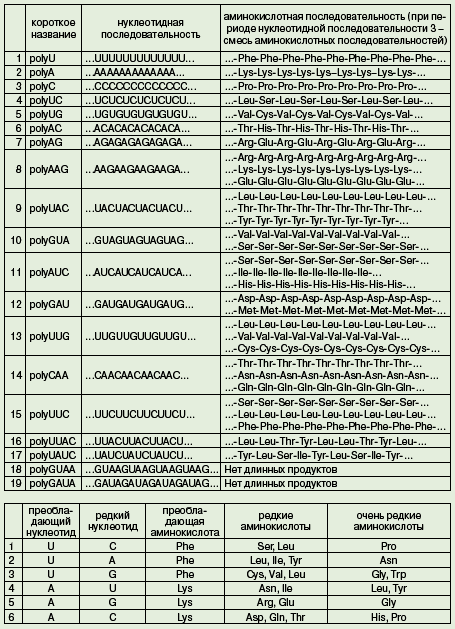
Представлены два типа данных. Во-первых, показано, какие аминокислотные последовательности кодируются регулярными нуклеотидными последовательностями с известной структурой (однако фаза считывания неизвестна!). Во-вторых, показано примерное соотношение аминокислот в продуктах трансляции нерегулярных последовательностей с известным соотношением нуклеотидов. Данные второго типа могут быть неполны: показаны не все встречающиеся аминокислоты, а соотношения сильно огрублены.
Задача состоит в том, чтобы установить как можно больше соответствий между кодонами (тройками нуклеотидов) и аминокислотами.
Представлены два типа данных. Во-первых, показано, какие аминокислотные последовательности кодируются регулярными нуклеотидными последовательностями с известной структурой (однако фаза считывания неизвестна!). Во-вторых, показано примерное соотношение аминокислот в продуктах трансляции нерегулярных последовательностей с известным соотношением нуклеотидов. Данные второго типа могут быть неполны: показаны не все встречающиеся аминокислоты, а соотношения сильно огрублены.
Задача состоит в том, чтобы установить как можно больше соответствий между кодонами (тройками нуклеотидов) и аминокислотами.
преобла- дающий нуклеотид редкий нуклеотид преобла- дающая аминокислота редкие аминокислоты очень редкие аминокислоты
1 U C Phe Ser, Leu Pro
2 U A Phe Leu, Ile, Tyr Asn
3 U G Phe Cys, Val, Leu Gly, Trp
4 A U Lys Asn, Ile Leu, Tyr
5 A G Lys Arg, Glu Gly
6 A C Lys Asp, Gln, Thr His, Pro
Ответ на стр. 11
Михаил Гельфанд
самым, каковы могли быть самые первые этапы этой эволюции.
По-видимому, есть три основных механизма смены аминокислоты, кодируемой кодоном. Первый возникает, когда какой-то кодон вообще не используется в генах какого-то организма. Тут существенно, что в силу вырожденности кода большинство аминокислот кодируется сразу несколькими кодонами, и частоты этих кодонов могут сильно отличаться в силу различных причин. Например, ДНК данного организма может иметь очень неравномерный состав нуклеотидов, и кодоны, включающие относительно избегаемые нуклеотиды, будут относительно редки. Если в силу статистического дрейфа частот такой редкий кодон вовсе исчезает из употребления, то в дальнейшем он может начать использоваться для кодирования другой аминокислоты без того, чтобы произошли изменения в кодируемых белках. Такой механизм, по-видимому, отвечает за некоторые диалекты кода, наблюдаемые в митохондриях — клеточных органеллах, которые имеют свою собственную ДНК, кодирующую небольшое количество генов.
Второй механизм — это превращение стоп-кодона в кодон, коди-
рующий аминокислоту. Это уже не так безболезненно, ведь все гены, которые заканчиваются этим стоп-кодоном, будут транслироваться дальше, и на конце у кодируемых белков появятся случайные дополнения. Но, оказывается, многие гены «для страховки» заканчиваются не одним стоп-кодоном, а сразу двумя — дело в том, что даже и в обычной ситуации стоп-кодоны иногда по ошибке считываются как кодирующие аминокислоту, и двойные стопы повышают надежность остановки. Из-за таких двойных стопов доля удлиняемых белков может быть не так уж велика, и вид успевает приспособиться за счет случайных мутаций, в результате которых возникают стоп-кодоны в нужных местах.
Как это ни парадоксально, довольно частым вариантом может оказываться еще один, третий, -когда какое-то время кодон используется для кодирования сразу двух аминокислот. Считывание его при этом неоднозначно, что, казалось бы, крайне невыгодно для клетки: в ней образуется множество белков, содержащих не ту аминокислоту, которая нужна в данном белке. Тем не менее, такие случаи были замечены у некоторых грибов, близких родственников дрожжей.
После обнаружения диалектов генетического кода появилось множество работ, в которых предлагались различные модели происхождения современного кода из более простых вариантов. Многие из предложенных моделей были весьма остроумны и хорошо согласовались с имеющимися данными. В частности, было показано, что код обладает свойствами помехоустойчивости: случайные мутации в генах (или ошибки трансляции) не очень сильно меняют физико-химические свойства аминокислот. На основании симметрий, наблюдаемых в коде, и биохимических представлений о путях биосинтеза аминокислот была предложена очередность, с которой аминокислоты начинали использоваться в белках и включались в кодовую таблицу.
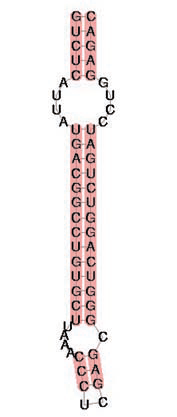
Настоящее потрясение пришло в 1986 г., когда сразу несколько групп обнаружили, что существует 21-я аминокислота, кодируемая генетически, а не возникающая в результате пост-трансляционных модификаций белков. Селеноцистеин — это вариант обычной аминокислоты цистеина, содержащий атом селен вместо обычного атома серы. Эта аминокислота встречается крайне редко, не более чем в паре десятков различных белков в одном организме. Все эти белки — ферменты, в которых селеноцистеин играет роль активного компонента функционального центра, и в этом качестве он существенно эффективнее, чем обычный цистеин. При этом в семействах родственных ферментов в одной и той же позиции у некоторых организмов встречается селеноцистеин, а у других — цистеин. Селеноци-стеин кодируется одним из стоп-кодонов (UGA), но чтобы этот кодон прочитался не как сигнал окончания трансляции, а как селено-цистеиновый кодон, в мРНК должен быть дополнительный структурный элемент (рис. 2). Взаимодействие этого элемента с комплексом, осуществляющим трансляцию, и приводит к включению в растущий белок селеноцистеина. До сих пор считалось, что UGA может кодировать селеноци-стеин либо стоп, но недавно в работе группы Вадима Гладышева из Университета Небраски было показано, что у инфузории Euplotes UGA кодирует селеноцисте-ин и обычный цистеин (см. заметку «Одноклеточный организм нарушил догму генетического кода» в ТрВ № 20 и поправку в ТрВ № 21).
Следует сказать, однако, что во всей шумихе, сопровождавшей работы, посвященные селеноци-стеину, была некоторая доля лукавства. Дело в том, что на самом деле во всех учебниках уже упоминалась одна дополнительная (двадцатая-с-половиной?) аминокислота. У бактерий трансляция всегда начинается с формилметионина -варианта одной из двадцати основных аминокислот, метионина. В начале гена формилметионин кодируется как обычным метиони-новым кодоном AUG, так и еще двумя кодонами, GUG и UUG, которые в середине гена кодируют калин и лейцин, соответственно. Тем самым, формилметионин имеет свой собственный набор кодонов и потому
вполне мог бы считаться самостоятельной аминокислотой. Однако, по-видимому, формилметионин никогда не рассматривали какотдель-ную аминокислоту, поскольку он встречается только в начале гена, тем более, что во многих белках он отщепляется при созревании, а у других отщепляется формильная группа и остается метионин. Таким образом, формилметионин, подобно букве «ё» или (бывшей) планете Плутон, так и оставался пасынком генетического кода.
Еще через какое-то время была обнаружена 22-я аминокислота, пирролизин. Этот вариант обычного лизина встречается у некоторых архебактерий и, как и селеноци-стеин, кодируется одним из стоп-кодонов, на этот раз UAG. Однако, в отличие от селеноцистеина, пиролизин был найден в очень ограниченной группе организмов. Про механизм, позволяющий клетке отличить пиролизиновый кодон от стопа, имеется только предположение, что он также использует специальную структуры РНК. UAG в организмах, имеющих пирролизин, редко используется как стоп, а если используется, то сразу или почти сразу после него следует один из двух других стоп-кодонов.
Разумеется, после открытия се-леноцистина и пирролизина появились основания подозревать, что на этом дело не остановится. Тем не менее, кажется, новых членов генетического кода ожидать не следует, во всяком случае среди организмов с полностью известными ДНК. Это показал систематический компьютерный анализ, предпринятый несколько лет назад Вадимом Гладышевым и его сотрудниками.
Дело вот в чем. Как уже упоминалось, селеноцистеину в родственных белках (из других организмов, например, вообще не имеющих се-леноцистеина) может соответствовать цистеин. Тем самым, выписав друг под другом большое число генов, кодирующих эти белки, мы увидим, что при общем высоком уровне сходства кажется, что некоторые белки заканчиваются преждевременно: есть колонки, содержащие как цистеиновые кодоны, так и стоп-
кодоны (которые, как мы на самом деле знаем, кодируют селеноцисте-ин). При этом, в отличие от ситуаций, когда белок действительно укорочен по сравнению с родственными белками, сходство генов сохраняется и за этими стоп-кодонами. Аналогичная ситуация наблюдается и в случае пиролизина: в наборе родственных генов есть колонки, содержащие ли-зиновые и стоп (т.е. пирролизино-вые) кодоны.
Теперь ясно, как можно искать случаи дополнений в генетическом коде. Надо рассмотреть семейства родственных генов и целенаправленно анализировать ситуации, когда соответствующие позиции в разных генах кодируют либо (преждевременный) стоп, либо (преимущественно) какую-то одну аминокислоту, причем преждевременность стоп-кодона выражается в сохранении сходства белков после него. Кроме того, можно искать дополнительные тРНК (молекулы, участвующие в трансляции), узнающие стоп-кодоны. Это и было проделано — и, к разочарованию исследователей, ничего найдено не было (3).
Этот подход имеет одно тонкое место: он предполагает, что белки, содержащие нестандартную аминокислоту, имеют более обычных родственников. Вообще говоря, это не обязательно: можно представить себе,что тот же пиролизин был бы настолько необычен, что не мог бы быть заменен ни на какую из аминокислот без полной потери функции белка.
Ну и, конечно, с появлением все новых полных последовательно-
G.Gamow. Possible relation between DNA and protein structures. Nature. 1954. 173: 318-320.
F.H.C.Crick. On degenerate templates and the adaptor hypothesis. A note for the RNA Tie Club. 1955. http://profiles.nlm.nih.gov/SC/B/B/ G/F/_/scbbgf.pdf A.V.Lobanov et al. Is there a twenty third amino acid in the genetic code? Trends Genet. 2006. 22: 357-360.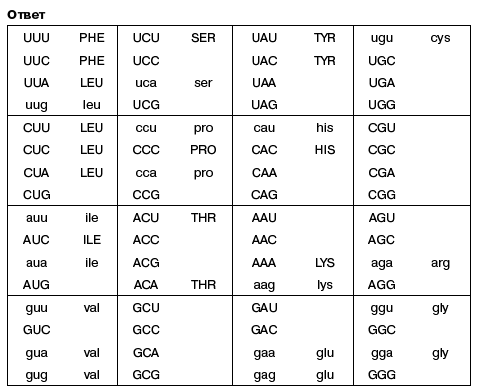
- Большими буквами показаны соответствия, однозначно устанавливаемые из комбинаторных соображений. Строчными буквами показаны соответствия, для установления которых использовано наблюдение, что кодоны, отличающиеся только в третьей позиции, часто кодируют одну и ту же аминокислоту.
