
В Институте мировой культуры МГУ на конец декабря назначена презентация нового онлайн-проекта — информационной системы «Сравнительная поэтика и сравнительное литературоведение» для изучения взаимосвязей русской и зарубежной поэзии (проект РНФ № 17–18–01701) [1]. Уже сейчас пользователям доступно более 2000 стихотворений (европейских оригиналов и их русских переводов), 60 научных изданий (монографий, сборников, отдельных статей и критических изданий с комментариями и сопроводительными статьями), в них — около 270 отдельных статей. Общее число авторов, чьи произведения представлены в системе, — 180 исследователей и 480 поэтов и переводчиков. Однако главная инновация не число произведений, а способы их представления.
В современных гуманитарных науках часто говорят о двух родственных проблемах: критическом увеличении объема художественных текстов, доступных для анализа, и перепроизводстве исследовательских текстов при отсутствии эффективной аккумуляции уже имеющегося знания. Первую проблему пытаются решить с помощью инструментов компьютерного анализа (см., например, «дальнее чтение» Франко Моретти). Пусть машины читают и анализируют данные, а человек работает с результатами этого анализа; для того чтобы эти данные появились, нужно создавать большие корпусы текстов того или иного типа (жанра, периода и т. д.). Вторую задачу отчасти решают специализированные электронные библиотеки, куда материалы отбираются по областям знания. Самые простые примеры таких библиотек — сайты, посвященные отдельным авторам, где собраны их произведения и критическая литература. Такие проекты пытаются бороться с хаосом гуманитарного знания, но помогают ли они конкретным научным областям двигаться вперед, а не стоять на месте, стараясь не растерять накопленное и не утонуть в тоннах новой информации? Позволяет ли современная цифровизация узнавать о культуре и ее механизмах новое? Или вскоре мы просто обнаружим себя заваленными тоннами текстов и тривиальных фактов, утратившими способность к глубокому анализу и растеряв всю научную эрудицию в расчете на помощь интернета?
Для конкретного раздела филологии — сравнительного литературоведения — digital humanities пока не предлагает почти ничего. Из уже ставших традиционными баз-библиотек и баз-корпусов литературной компаративистике полезны параллельные корпусы (как русско-французский поэтический корпус 1800–1830 годов [2] или Параллельный корпус Национального корпуса русского языка [3]). Однако специализированных сервисов для этой области науки до последнего времени не существовало. Такая система — первое электронное хранилище сведений о взаимодействии разноязычных стихотворных текстов (русских и написанных на романских языках — французском, итальянском, испанском) — была создана в 2017–2019 годах в МГУ имени М. В. Ломоносова.
Как она устроена?
В ней содержатся, прежде всего, русские поэтические переводы с европейских языков, их иноязычные оригиналы, научная литература по сравнительной поэтике и сравнительному литературоведению, а также разная дополнительная информация. Стихотворные тексты, как русские, так и иноязычные, сопровождаются разметкой, описано их формальное устройство (метрика и строфика), внесена информация о дате создания и публикации, об авторе. Система позволяет находить нужные тексты, используя стиховедческие параметры — те самые сведения о метрике и строфике. В этом отношении новая система подобна корпусам стихотворных текстов (таким, как Поэтический подкорпус уже упомянутого Национального корпуса русского языка [4] или Корпус чешского стиха [5]). Новизна системы заключается в том, что в ней объединены параллельный корпус поэтических текстов и электронная библиотека научных изданий.
Всю информацию представляют четыре взаимосвязанных раздела (подсистемы):
1) Корпус параллельных текстов,
2) цифровая Библиотека комментированных изданий поэтических переводов и их оригиналов, а также книг и статей по сравнительной поэтике,
3) Энциклопедия (систематизированные биобилиографические сведения о поэтах, переводчиках и исследователях-компаративистах),
4) Тезаурус (структурированный глоссарий, который содержит термины, встречающиеся в научной литературе, описывает их значение и приводит примеры употребления).
Интерфейс системы реализован на трех языках — русском, английском и испанском.
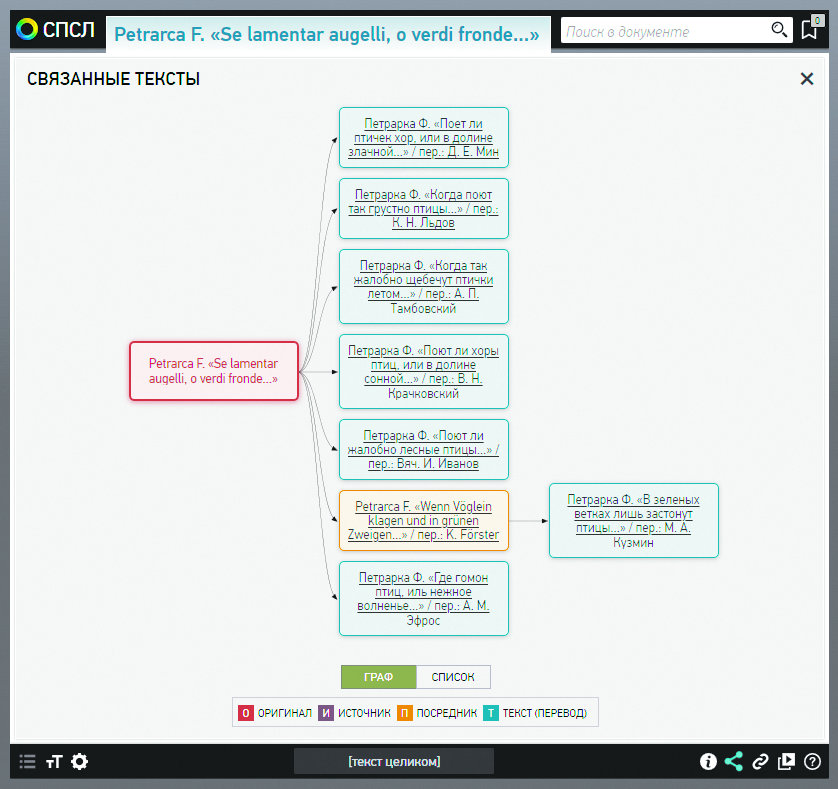
Корпус содержит поэтические произведения, переведенные на русский язык с французского, итальянского и испанского, их оригиналы и переводы-посредники на немецкий, английский и другие языки [6]. Кроме того, в систему добавляются и более старые (греческие, римские) тексты, которые были источниками романских оригиналов русских переводов (как, например, оригиналы текстов из древнегреческой антологии, переведенные Вольтером). Поэтому в корпусе выделяются четыре типа текста: T = перевод, O = оригинал, П = посредник, И = источник. Они не просто загружены в систему — связи между ними эксплицированы и представлены в виде кластеров (пучков отношений). Визуализированные ссылки генерируются автоматически на основе соответствующих метаданных. Они представлены в виде списка и в виде графа. Например, можно посмотреть историю переводов 279-го сонета Петрарки [7]. Помимо русских переводов, в кластер включен немецкий текст-посредник: один из переводчиков, М. Кузмин, переводил текст не с итальянского оригинала, а с немецкого перевода. Ссылки вызываются нажатием кнопки «отношения» на панели инструментов. Имеется возможность параллельного просмотра (связанные тексты могут быть загружены в левое или правое окно). Но это еще не всё: пользователю интересно понять, например, почему Кузмин, прекрасно знавший итальянский язык, переводил Петрарку с немецкого. Об этом можно узнать из статьи П. В. Дмитриева, опубликованной в 1996 году в «Новом литературном обозрении». Эта статья включена в электронную библиотеку СПСЛ, а между нею и текстами в Корпусе установлены связи. Эти связи (они вызываются нажатием соответствующей кнопки на панели управления) семантизированы: пользователь не просто видит гиперссылки, а понимает, что одна из них ведет от текста в Корпусе к комментированному изданию этого текста в Библиотеке; другая — непосредственно к комментарию; третья — к научной статье или монографии об этом тексте и к конкретным страницам, на которых о нем говорится; четвертая — от научной статьи к конкретным стихотворным текстам, которым она посвящена, и т. д.
|
Sonetto CCLXXIX Se lamentar augelli, o verdi fronde là ’v’io seggia d’amor pensoso, et scriva, «Deh, perché inanzi ’l tempo ti consume?» Di me non pianger tu; ché’ miei dì fêrsi Francesco Petrarca |
Zweihundert sieben und dreißigtes Sonett Wenn Vöglein klagen und in grünen Zweigen (übersetzt von Karl Förster) |
Сонет 279 В зеленых ветках лишь застонут птицы, Мне же стихи любовь на мысль приводит, — Зачем же упреждать страданий сроки? — Не плачь, мой друг, ведь те, кто умирают, (перевод Михаила Кузмина) |
Библиотека включает тексты в виде электронных факсимиле всего печатного издания или его фрагмента (для отдельных статей) [8]. Тексты при этом распознаны, их можно копировать и по ним можно проводить поиск — так же как и по текстам в Корпусе.
Цель всей этой сложной многосоставной системы — объединить возможности цифровых библиотек и параллельных корпусов и превратить полученный инструмент в семантизированный гипертекст, «семантическую сеть».

Комментирует руководитель проекта Игорь Пильщиков (докт. филол. наук, вед. науч. сотр. ИМК МГУ, проф. UCLA, ст. науч. сотр. ТЛУ):
— Главная особенность новой системы — в принципах хранения информации и форме представления разноязычных переводов одного текста как текстов взаимосвязанных. Для этого мы придумали новый формат. Он так прост, что кажется его должны были создать раньше, тем не менее, насколько нам известно, это не так. Мы называли этот формат сначала «цепочками» текстов, а сейчас используем новый более точный термин — «кластеры», или «пучки».
Обычно, когда мы говорим о взаимоотношении культуры-источника и культуры-результата, текста-источника и текста-результата, мы ориентируемся на бинарное представление этих отношений.
Иногда такая бинарная картина отягощается дополнительными элементами. Между текстами могут возникать посредники или несколько посредников. Очевидно, что трансфер из культуры в культуру, из языка в язык сопровождается трансформациями на разных уровнях текста, и мы можем их изучать. Традиционных способов сохранения информации о взаимоотношениях текстов типа «оригинал — перевод» или «оригинал — посредник — перевод» немного.
Недостатки очевидны и многочисленны. У статей и комментариев к изданию перевода очевидный недостаток — это необходимость приложить дополнительные усилия, для того чтобы найти оригинал. Книги-билингвы, кажется, хорошо подходят для демонстрации взаимоотношений между двумя текстами, но в них неудобно представлять тексты-посредники. Они в лучшем случае упоминаются в комментарии. Очевидно, что осуществлять целое издание с демонстрацией трех-четырех параллельных текстов из-за отдельных небольших стихотворений (только некоторые опирались на тексты-посредники) в доцифровую эпоху было фактически невозможно. Такие тексты часто составляли иллюстративный материал отдельных научных работ, но не комментированных изданий. Другая особенность традиционного билингвального представления состоит в том, что в случае ориентации издания на представление наследия иностранного автора при существовании нескольких переводов редактор-составитель должен выбрать текст, который будет непосредственно идти параллельно в издании. Другие переводы в лучшем случае помещаются в раздел приложений, оригинала рядом нет. Таким образом, традиционная эдиционная практика располагает скромными возможностями для демонстрации сложных межтекстовых отношений. О неудобстве сличения переводов друг с другом и с оригиналом можно и не говорить.
Если речь идет не о взаимоотношениях «текст — перевод», а о более сложной схеме, то они фактически никогда не представляются полными текстами. В реальности же текстовые взаимоотношения могут напоминать генеалогические и быть очень причудливыми.
Как я уже сказал, в нашей системе мы решили называть такие группы текстов «пучками», или «кластерами». Какие у такого решения плюсы? Во-первых, не нужно осуществлять выбор основного перевода. Во-вторых, все переводы могут быть выведены на экран для параллельного просмотра. В-третьих, отношения между ними могут быть представлены в виде наглядной схемы.
Параллельные корпусы тоже дают возможность сравнивать тексты, но не выстраивают схему взаимодействия. Основная задача, решаемая с помощью параллельного корпуса, — исследование лингвистических особенностей перевода, а не истории текста в культуре.
Кластер — это новый тип хранения и визуализации информации по истории переводных текстов. В будущем при увеличении объема системы мы сможем по-новому смотреть на взаимодействие литератур. Построив систему, мы увидели, что цепочки сцепляются в кластеры. Действительно, теоретики перевода говорят о парадоксе: единственному оригиналу всегда соответствует множество переводов, ни один не адекватен оригинальному тексту полностью, но представляет собой одну из многих возможностей воссоздания оригинала. Уникальная структура оригинала разнообразно отражается в наборе отображений-переводов. «Кластерная теория перевода» или «кластерный метод при написании истории перевода» могут исходить из того, что этот набор отображений сам является многомерной структурой и может быть представлен в виде графа.
Вера Полилова,
канд. филол. наук
- cpcl.feb-web.ru/
- nevmenandr.net/fr/
- ruscorpora.ru/new/search-para-en.html
- ruscorpora.ru/new/search-poetic.html
- versologie.cz/v2/web_content/corpus.php?lang=en
- cpcl.feb-web.ru/corpus/
- cpcl.feb-web.ru/text/petrarka_sonety_2004@s-258-1/
- cpcl.feb-web.ru/library/
